Sommaire
Trot Monté : déploiement du nouveau modèle de pronostics IA
Comme évoqué ces derniers jours, nous travaillons sur la publication de nos modèles de prédiction (trot monté, attelé, plat, haies), lesquels présenteront une amélioration notable, non seulement dans la prédiction globale mais aussi dans la capacité du modèle à identifier plus facilement les potentiels outsiders.
Nous avons pris de l'avance sur notre calendrier de déploiement puisque dès ce jeudi 19 décembre, les prédictions pour la discipline Trot Monté sont publiées. Suivra au cours du week-end prochain le déploiement des nouvelles prédictions pour le Plat
Quels sont les principaux changements ?
Nous avons intégré dans nos données de nouvelles sources et caractéristiques visant à permettre à l'IA de détecter de nouvelles corrélations entre le cheval et sa performance :
- Géographie : Intégration d'une métrique prenant en compte la distance entre le haras et le champ de course. Cet indicateur, que l'on peut retrouver sur le site de l'Institut Français du Cheval, bien qu'à nuancer avec discernement, offre une amélioration tangible de la détection d'outsiders.
- Plafond des gains : C'est un sujet controversé et nulle question de débat sur la notion de "faire le tour", mais l'objectif pour notre IA est de faire le lien entre la différence entre les gains du cheval et le plafond des gains afin de déterminer si le changement peut affecter les engagements futurs du cheval.
- Indice de Gini : Initialement conçu en économie pour mesurer l’inégalité des revenus, il a été adapté dans notre contexte pour évaluer la distribution des performances d’un cheval sur plusieurs courses. Si un cheval affiche un Gini élevé, cela signifie que ses résultats passés sont très inégaux : parfois excellent, parfois très en retrait. Cet indicateur aide le modèle à modérer ou à ajuster la confiance portée à certaines informations. Un cheval très inégal peut présenter plus de risques d’une contre-performance, même s’il a récemment gagné.
Améliorations Globales
Notre nouveau modèle est bien meilleur que le précédent. En moyenne, il est environ 9% plus performant :
Précision : Le modèle est 10% plus précis. Cela signifie que, parmi les chevaux qu'il identifie comme ayant de bonnes chances de gagner ou de se placer, il se trompe moins souvent. En clair, il fait moins d'erreurs dans ses prévisions.
Capacité à repérer les bons chevaux : Le modèle est également 4% meilleur pour identifier tous les chevaux ayant une chance de gagner ou de se placer, même ceux qui sont moins évidents. Il laisse donc moins de candidats potentiels "passer entre les mailles du filet".
Performance globale : Par la synergie de ces deux points (qui ne s'additionne pas), le modèle affiche une amélioration de 13% dans ses résultats globaux. Cela montre qu’il est devenu bien plus équilibré : il fait moins d’erreurs tout en repérant davantage de chevaux compétitifs.
Quelle incidence sur les prédictions passées
La méthodologie de prédiction reste strictement la même. Et la modification doit être autant que possible proche de votre lecture habituelle. Néanmoins, l'IA sera plus confiante et plus audacieuse.
Prenons un exemple avec une course de trot monté pour la journée du lancement : la R3C1 au Meslay du Maine.
Voici l'ancienne version du modèle :
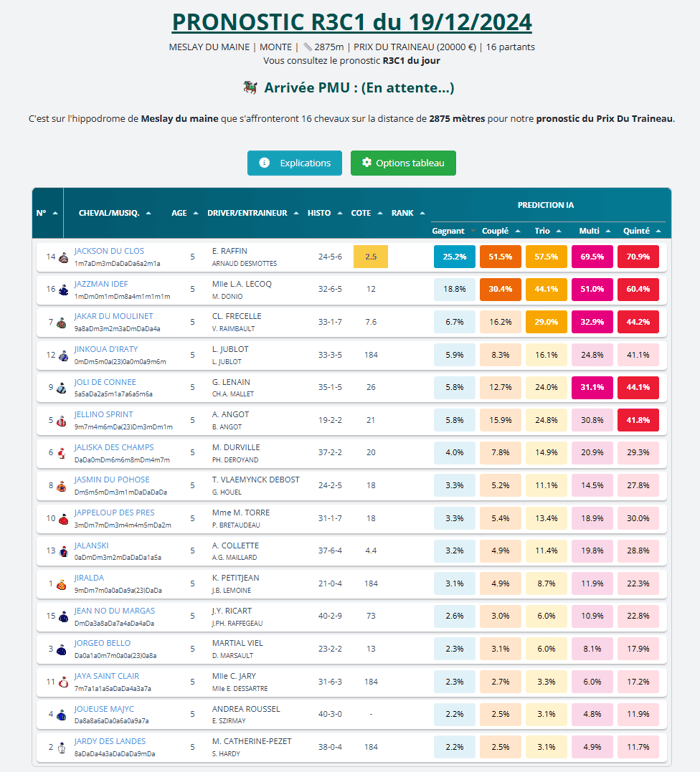 Ancien modèle de prédiction
Ancien modèle de prédictionEt voici la prédiction à partir de cette nouvelle version :
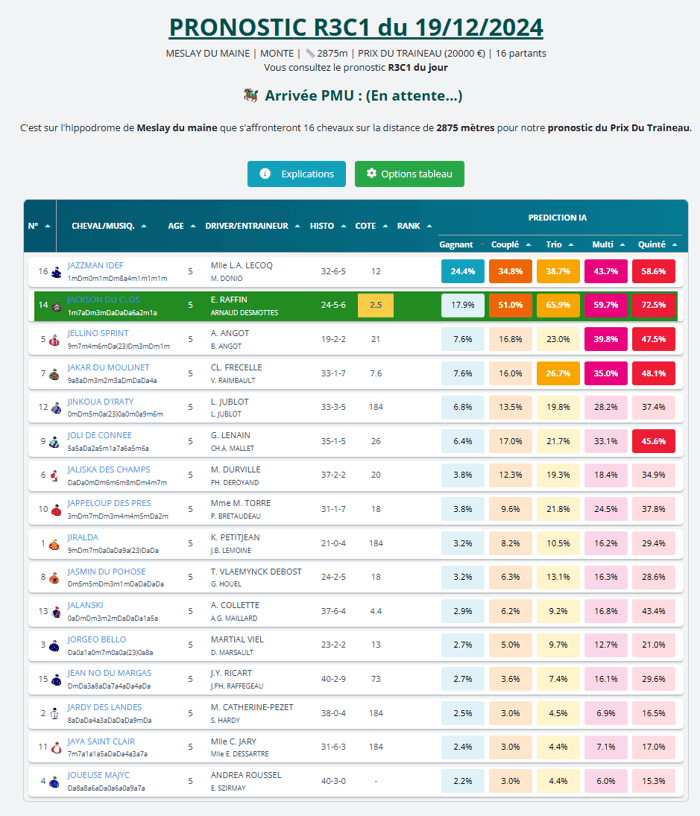 Nouvelle Version
Nouvelle Version Constat :
Le système a détecté une très forte chance pour le couplé et le placé pour le 14 Jackson du Clos. On pourrait penser qu'il devrait être le mieux placé pour être gagnant mais l'IA en décide autrement, relatif aux performance de Lou-Ann Lecoq qui a déjà gagné 6 fois avec Jazzman Idef et avec une cote d'outsider.
Mise à jour de 12h00 : La nouvelle version s'est parfaitement comportée en donnant le couplé gagnant avec la victoire du 16 Jazzman Idef avec une cote définitive de 4/1 accompagné du 14 Jackson du clos.
Comment le modèle est-il testé ?
Pour la culture data science et sans rentrer dans trop de jargon technique :
- Entraînement : Nous utilisons toutes les courses de trot monté de 2008 à ce jour pour entraîner le modèle. Cela lui a permis d'apprendre à partir de nombreuses courses passées.
- Validation : Nous avons réservé quatre mois de données pour vérifier que le modèle fonctionne bien sur des courses qu'il n'a jamais vues auparavant.
- Tests : Enfin, nous avons utilisé les deux derniers mois de données pour tester le modèle dans des conditions réelles.
Quel type de modèle est utilisé ?
Nous utilisons des algorithmes de machine learning avancés tels que XGBoost, LightGBM et CatBoost pour construire un modèle de stacking. Nous employons également la bibliothèque Optuna pour rechercher les meilleurs hyperparamètres. Le trot monté est la discipline la plus légère de notre base de données en termes de nombre de courses, mais elle comporte tout de même 400 000 enregistrements.
Cependant, le travail ne consiste pas seulement à faire tourner des modèles d'IA à partir de données brutes. Il faut préparer et nettoyer soigneusement les données, créer des caractéristiques dérivées (que l'on nomme dans le jargon "feature engineering"). En finalité, nous avons environ 170 caractéristiques, mais je m'y attarderai plus longuement dans un prochain article dédié pour ceux qui sont intéressés par les techniques d'IA.
Ensuite, nous faisons tourner le modèle, procédons à une calibration isotonique, et lançons quotidiennement les prédictions. À ce propos, je profite de l'occasion pour répondre à une question reçue par mail :
Pourquoi les prédictions du lendemain sont-elles réactualisées le matin même ?
Les prédictions de turf.bzh tournent chaque nuit, en actualisant quotidiennement les classements ELO de l'ensemble des protagonistes d'une course (par exemple, si le jockey a couru plusieurs courses la veille, son ELO sera différent et aura une conséquence sur le taux de probabilité du cheval qui montera le lendemain).
Il en est de même lorsqu'il y a un changement de jockey, ou que certaines informations sont actualisées tardivement (comme le ferrage, le changement de jockey, les non partants (et donc le nombre de partants) et les chevaux supplémentés).
Toutefois, les prédictions à J et J+1 ne présentent pas de changements radicaux, mais nous vous conseillons de prioriser les pronostics IA publiés chaque matin entre 6h et 8h.
Transparence sur les limitations du modèle
Aussi performant soit-il, notre modèle n’est pas omniscient et ne peut prendre en compte certaines composantes irrégulières. Il repose sur des données et des tendances et performances historiques, et ne peut prévoir l’imprévu. Une blessure, un changement de stratégie de course, des conditions climatiques extrêmes ou un événement inattendu peuvent affecter les résultats réels. Le modèle offre une vision probabiliste, pas une certitude absolue. Il faut donc utiliser ses prédictions comme un éclairage supplémentaire, un outil d’aide à la décision, plutôt que comme une vérité figée.
Mise en Production
Nous espérons mettre en production tous nos modèles pour le 27 décembre 2024 prochain, sous réserve du bon comportement des serveurs de calculs. Le modèle du trot attelé étant le plus chargé puisqu'il a besoin d'environ 120 heures pour s'entraîner.
Merci de votre confiance et de votre patience. Nous restons à votre disposition pour toute question.